
A composable AI coding stack is an architectural framework for building artificial intelligence systems by assembling independent, reusable, and interoperable AI components and services through well-defined interfaces. It replaces a monolithic AI system with a flexible assembly of interchangeable parts, embracing modularity, API-driven design, and orchestration.
This approach allows organizations to rapidly develop, update, and scale AI applications while leveraging best-of-breed tools and models. This guide, current as of early 2026, provides the definitive deep dive into its principles, mechanics, tools, and implementation.
TL;DR: The Composable AI Advantage
Quick Takeaways on Composable AI Coding Stacks
If you’re in a hurry, here are the core, actionable benefits of a composable AI coding stack:
- Modularity Replaces Monoliths: Systems are built from independent components—like pre-trained models, data pipelines, and microservices—that you can swap, update, or scale without rewriting the entire application.
- Development Speed Surges: You integrate and test new AI capabilities in days or weeks, not months, by connecting off-the-shelf components via APIs rather than building them from scratch.
- Future-Proofing is Built-In: When a superior model (e.g., GPT-5) or framework appears, you can integrate it as a new component alongside your existing stack, protecting your investment.
- Reusability Drives Efficiency: A well-designed component (e.g., a sentiment analysis service) can be wired into a customer support bot, a social media monitor, and a product feedback analyzer, amplifying its value.
- Operational Control Improves: Components can be monitored, updated, and scaled independently. A failing model inference endpoint can be throttled or swapped without bringing down your entire AI application.
- Democratization of AI: Frontend developers can use complex AI capabilities by simply calling an API, allowing specialists to focus on building and refining the core components.
Key Takeaways: Decisions and Insights for Composable AI
Strategic Implications of the Composable AI Coding Stack
Beyond the technical specifications, adopting a composable AI philosophy reshapes strategy:
- AI is an assembly problem. Competitive advantage increasingly comes from how effectively you select, integrate, and orchestrate AI components, not just from coding a bespoke model.
- Your most critical asset is a robust integration layer. The value of your composable AI coding stack is defined by the reliability, security, and observability of the connections between components. Invest in API gateways, workflow orchestrators, and clear data contracts.
- Component marketplaces are the new dependency managers. Platforms like Hugging Face, Replicate, and cloud AI service catalogs are becoming de facto package managers for AI capabilities. Your team’s ability to evaluate and incorporate these external components is a key skill.
- Data governance is non-negotiable. When data flows through a network of loosely coupled services—from feature stores to multiple model APIs—maintaining data quality, lineage, and compliance requires a deliberate, system-wide strategy.
- Skill sets must migrate from monolithic development to orchestration. You need engineers adept at designing workflows, managing API contracts, and debugging distributed systems, alongside your data scientists and ML engineers.
What is a Composable AI Coding Stack? Understanding the Core Concept
Defining the Composable AI Coding Stack
A composable AI coding stack is an architectural pattern for constructing production AI systems by assembling discrete, loosely coupled, and independently deployable AI components. These components are exposed as services with standardized interfaces—predominantly RESTful or gRPC APIs, but also via message queues or event streams. A component can be virtually any AI-related capability: a containerized machine learning model served by BentoML or KServe, a vector database search service, a feature transformation pipeline hosted on AWS Lambda, a call to the Anthropic Claude 3.5 API, or a custom Python service for business logic.
The stack is “composable” because these components are designed as building blocks that can be connected in various sequences and configurations to form different applications. The connection logic—the “glue”—lives in an orchestration layer (e.g., Apache Airflow, Prefect) or within the application code itself, which calls these services. This stands in direct opposition to a monolithic codebase where data preprocessing, model inference, and business logic are intermingled, compiled, and deployed as a single, indivisible unit.
The Pillars of a Composable AI System
Six core principles underpin a robust composable AI coding stack:
- Modularity: Each component has a single, well-defined responsibility (e.g., “generate embeddings,” “detect anomalies,” “retrieve context”). Its internal implementation can change without affecting other components, as long as its interface remains stable.
- Reusability: A component is built to be used multiple times across different applications. An image classification service could be used by a content moderation system, a product catalog tagging tool, and a social media analytics dashboard.
- Interoperability (API-Driven): Components communicate through explicit, versioned contracts. This is typically achieved with OpenAPI specifications for REST APIs or Protobuf definitions for gRPC, ensuring components written in different languages (Python, Go, Java) can work together seamlessly.
- Scalability: Components can be scaled independently based on demand. The LLM inference component might need to scale horizontally under heavy user load, while the data validation component does not.
- Flexibility: The stack can evolve incrementally. You can replace a legacy fraud detection model with a newer one, or add a new real-time translation service, without a full system rewrite.
- Abstraction: The complexity of a component is hidden behind its interface. A consumer doesn’t need to know if a sentiment analysis component uses a fine-tuned BERT model or the OpenAI API; it just sends text and receives a sentiment score.
Why the Composable AI Coding Stack Matters Now: A Paradigm Shift
Current Drivers for Composable AI Adoption
The urgency around composable AI coding stacks isn’t theoretical; it’s driven by concrete market and technological pressures.
- The Pace of AI Innovation is Unsustainable for Monoliths. New foundational models, specialized APIs (for code generation, speech synthesis, etc.), and open-source frameworks are released weekly. A monolithic application tied to a specific model version (e.g., TensorFlow 2.8) becomes a legacy system almost immediately. A composable stack lets you treat these innovations as pluggable modules.
- Demand for Tailored AI Solutions is Exploding. Businesses don’t want a generic chatbot; they want an agent that understands their proprietary data, follows their business rules, and integrates with their CRM. Building this monolithically is prohibitive. A composable AI coding stack allows you to combine a general-purpose LLM, a private retrieval-augmented generation (RAG) component, a workflow engine for business logic, and a CRM connector.
- Time-to-Market is a Critical Competitive Metric. The ability to prototype, test, and deploy an AI feature in weeks, not quarters, is a decisive advantage. Composable architecture, by reusing existing components and integrating third-party services, drastically shortens development cycles.
- The Rise of Specialized AI-as-a-Service. Why build and maintain a computer vision model when Google Cloud Vision, AWS Rekognition, or a fine-tuned model from Roboflow offer robust APIs? The composable approach views these services as first-class components in your stack.
- MLOps Maturity Enables It. Tools for model registry (MLflow), serving (Seldon Core), and orchestration (Kubeflow Pipelines) have matured, providing the operational backbone needed to manage a fleet of independent AI components reliably.
Market Trends Fueling Composable AI
Several macro-trends cement composable AI as the dominant architectural pattern for the late 2020s:
- Proliferation of Pre-trained and Foundation Models: Hugging Face hosts over 500,000 models as of 2026. The challenge is no longer “can we train a model?” but “how do we operationalize and integrate the right model?”
- Ubiquity of Serverless and Containerization: Technologies like Docker, Kubernetes, and serverless functions (AWS Lambda, Google Cloud Run) provide the perfect deployment unit for an AI component, offering isolation, scalability, and simple management.
- The API Economy Comes to AI: Virtually every significant AI capability is now available via an API—from GPT-4 and Claude 3 to Stable Diffusion and Whisper. Building an AI application is increasingly an exercise in API orchestration. You can learn more about integrating AI tools via Python APIs for seamless implementation.
- Shift from ‘Build’ to ‘Assemble and Customize’: Enterprises are prioritizing agility over total ownership. The strategic focus is on proprietary data, domain-specific fine-tuning, and unique workflow orchestration, while leveraging commoditized AI capabilities from the ecosystem.
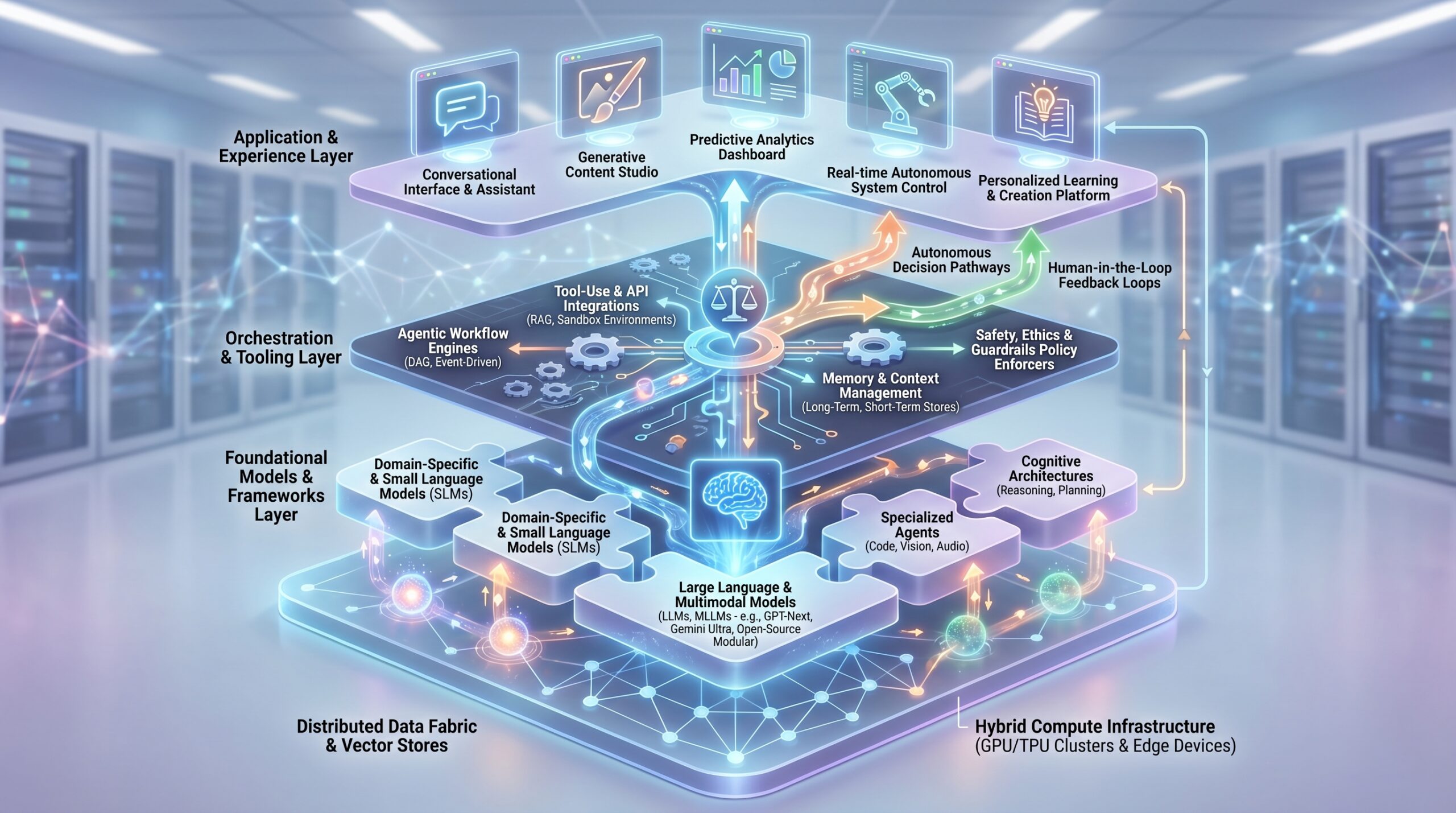
How a Composable AI Coding Stack Works: Mechanics of Modularity
Architectural Layers of a Composable AI Stack
A mature composable AI coding stack organizes components into logical layers. Note that these are logical, not physical; a component in the “Model Layer” might be deployed in the same Kubernetes cluster as an “Orchestration Layer” service.
- Data Layer: This is the source of truth and the preparation layer. Key components include Feature Stores (Feast, Tecton, Hopsworks) for managing consistent, real-time features; Vector Databases (Pinecone, Weaviate, Qdrant) for storing embeddings for semantic search; and Data Pipelines (Apache Spark jobs, dbt models, Fivetran syncs) that feed clean data into the system.
- Model Layer: This is where AI/ML intelligence resides. It contains Model Registries (MLflow, Weights & Biases) for versioning and lineage; Inference Services (containerized models served via BentoML, TorchServe, or Seldon Core); and External AI APIs (OpenAI, Anthropic, Cohere, Google Vertex AI). This layer is the most dynamic, with components frequently being added or upgraded.
- Orchestration & Integration Layer: This is the “central nervous system” that composes the stack. It includes Workflow Orchestrators (Apache Airflow 2.8, Prefect 3.0, Temporal) that define and execute sequences of component calls; API Gateways (Kong, Apigee) that manage routing, authentication, and rate-limiting for internal APIs; and Event Streaming Platforms (Apache Kafka, AWS EventBridge) for reactive, event-driven composition.
- Application Layer: This is the user-facing interface that consumes the orchestrated AI capabilities. It could be a web application (React, FastAPI), a mobile app, an internal tool, or even another API. Its primary role is to trigger workflows and present results.
Layers of a Composable AI Coding Stack
- Application Layer: User-facing interface (Web App, Mobile App, Internal Tool)
- Orchestration & Integration Layer: Workflow Orchestrators (Airflow, Prefect, Temporal), API Gateways (Kong, Apigee), Event Streaming (Kafka)
- Model Layer: Model Registries (MLflow), Inference Services (BentoML, Seldon Core), External AI APIs (OpenAI, Anthropic)
- Data Layer: Feature Stores (Feast, Tecton), Vector Databases (Pinecone, Weaviate), Data Pipelines (Spark, dbt)
Component Interaction and Orchestration in Composable AI
The magic—and complexity—lies in how these independent components interact. Two dominant patterns emerge:
- Orchestrated (Synchronous/Asynchronous) Workflows: A central orchestrator (e.g., an Airflow DAG or a Temporal workflow) acts as the conductor. It calls Component A (data fetch), waits for the result, passes it to Component B (feature transformation), then to Component C (model inference), and finally to Component D (result storage). This is ideal for batch processes, ETL pipelines, and complex multi-step AI tasks.
- Example: A nightly batch job to score customer churn risk. Orchestrator triggers a data extraction component from Snowflake, passes data to a feature engineering component, sends features to a registered XGBoost model for inference, and saves results to a database.
- Event-Driven (Choreographed) Composition: Components listen for events and act independently. When Component A finishes a task, it emits an event (e.g., “transaction_validated”) to a message queue. Component B, subscribed to that event, processes it and may emit its own event (e.g., “fraud_score_generated”). There is no central conductor.
- Example: A real-time fraud detection system. A transaction API (Component A) emits a “new_transaction” event. A feature retrieval service (B) listens, enriches the event with customer history. An anomaly detection model (C) scores it. An alert service (D) listens for “high_risk_score” events to notify analysts.
Data contracts are the critical glue. Every API call or event payload must adhere to a strict schema (defined with JSON Schema, Protobuf, or Avro). This ensures that when you swap out a sentiment analysis component, the new one still expects the same {"text": "string"} input and returns the same {"sentiment": "positive", "score": 0.95} output.
Building with Composable AI: A Step-by-Step Approach
Here’s a practical, iterative process for constructing a system on a composable AI coding stack:
- Decompose the AI Capability: Break your desired AI application (e.g., “intelligent document processor”) into discrete, logical tasks: document parsing, text extraction, classification, summarization, entity extraction, data validation.
- Source or Build Components: For each task, evaluate: build in-house, use open-source, or buy as a service. You might use the Azure Form Recognizer API for parsing, spaCy for entity extraction, and fine-tune a FLAN-T5 model for summarization. Each becomes a separate component.
- Define and Implement Interfaces: Package each component as a service with a clean API. Containerize it using Docker. Document the input/output contract and version it (e.g.,
/v1/summarize). - Design the Orchestration: Choose your pattern (orchestrated vs. event-driven) and implement it. Use Prefect to define the workflow that calls the parser, then the classifier, then the summarizer, in sequence.
- Deploy and Monitor Independently: Deploy each component to your infrastructure (Kubernetes, serverless). Implement centralized logging (ELK Stack), metrics (Prometheus/Grafana), and tracing (OpenTelemetry) to observe the entire chain.
Composable AI Workflow – Step-by-Step Construction
- Step 1: Decompose AI Capability: Breaking down a complex AI application into discrete, logical tasks (e.g., document parsing, classification, summarization).
- Step 2: Source or Build Components: Deciding whether to build in-house, use open-source, or buy a service for each decomposed task.
- Step 3: Define & Implement Interfaces: Packaging components as services with clean, documented, versioned APIs (e.g., using Docker).
- Step 4: Design Orchestration: Choosing an orchestration pattern (e.g., Prefect workflows) to define how components interact.
- Step 5: Deploy & Monitor Independently: Deploying each component to infrastructure and setting up centralized logging, metrics, and tracing.
Real-World Examples and Use Cases for Composable AI
Dynamic Personalization Engines with Composable AI
A monolithic personalization engine often becomes a brittle maze of rules and monolithic model code. A composable AI coding stack rebuilds it as a dynamic assembly line.
Scenario: An e-commerce platform needs real-time product recommendations on its homepage.
Composable Stack Workflow:
- A user visits the site. The web app (Application Layer) calls the “Personalization Orchestrator” (Orchestration Layer).
- The orchestrator simultaneously calls multiple components:
- User Profiling Service: Queries the Feature Store (Data Layer) for the user’s recent views, purchases, and demographic cluster.
- Real-Time Context Service: Analyzes the user’s current session clickstream using a lightweight model.
- Product Embedding Service: Fetches vector embeddings for the catalog from a Weaviate database.
- The orchestrator passes the aggregated user and context data to a Candidate Generation Model (Model Layer), which retrieves 100 relevant product IDs.
- These 100 candidates are sent to a Ranking Model, a more complex model (e.g., a deep learning ranker) that considers profit margin, inventory, and predicted conversion probability to order them.
- Finally, a Business Rule Filter (a simple logic component) removes out-of-stock items or applies promotional overrides.
- The ordered list of 20 products is returned to the homepage for display.
Key Composable Benefit: Each colored component can be updated independently. The ranking model can be retrained and deployed via the Model Registry without touching the user profiling service. A/B testing new candidate generation algorithms becomes trivial.
Intelligent Customer Support via Composable AI
Modern customer support bots are archetypal examples of composable AI, combining multiple specialized components.
Scenario: A customer messages, “My router keeps dropping the connection every evening.”
Composable Stack Workflow:
- Input Processing: The chat gateway sends the message to an Intent & Language Detection component (e.g., using Rasa or a Hugging Face model). It identifies intent: “Troubleshooting” and language: “English”.
- Context Retrieval: The intent triggers a Knowledge Base Search component. It uses the customer’s query to perform a semantic search over support articles via a vector database, retrieving relevant docs.
- Sentiment & Urgency Analysis: A parallel call to a Sentiment Analysis API (could be internal or from AWS Comprehend) gauges customer frustration.
- Response Generation: The intent, retrieved context, and customer history are formatted into a prompt and sent to an LLM Component (e.g., the Anthropic Claude API with a specific troubleshooting agentic persona). The LLM generates a empathetic, step-by-step response.
- Human Handoff Logic: If the sentiment score is critically low or the LLM’s confidence is below a threshold, a Handoff Decision component routes the conversation to a human agent, providing them with the full analysis context.
Key Composable Benefit: The LLM component can be swapped from GPT-4 to Claude to a fine-tuned internal model based on cost, performance, or policy. The knowledge base can be updated without redeploying the NLP models.
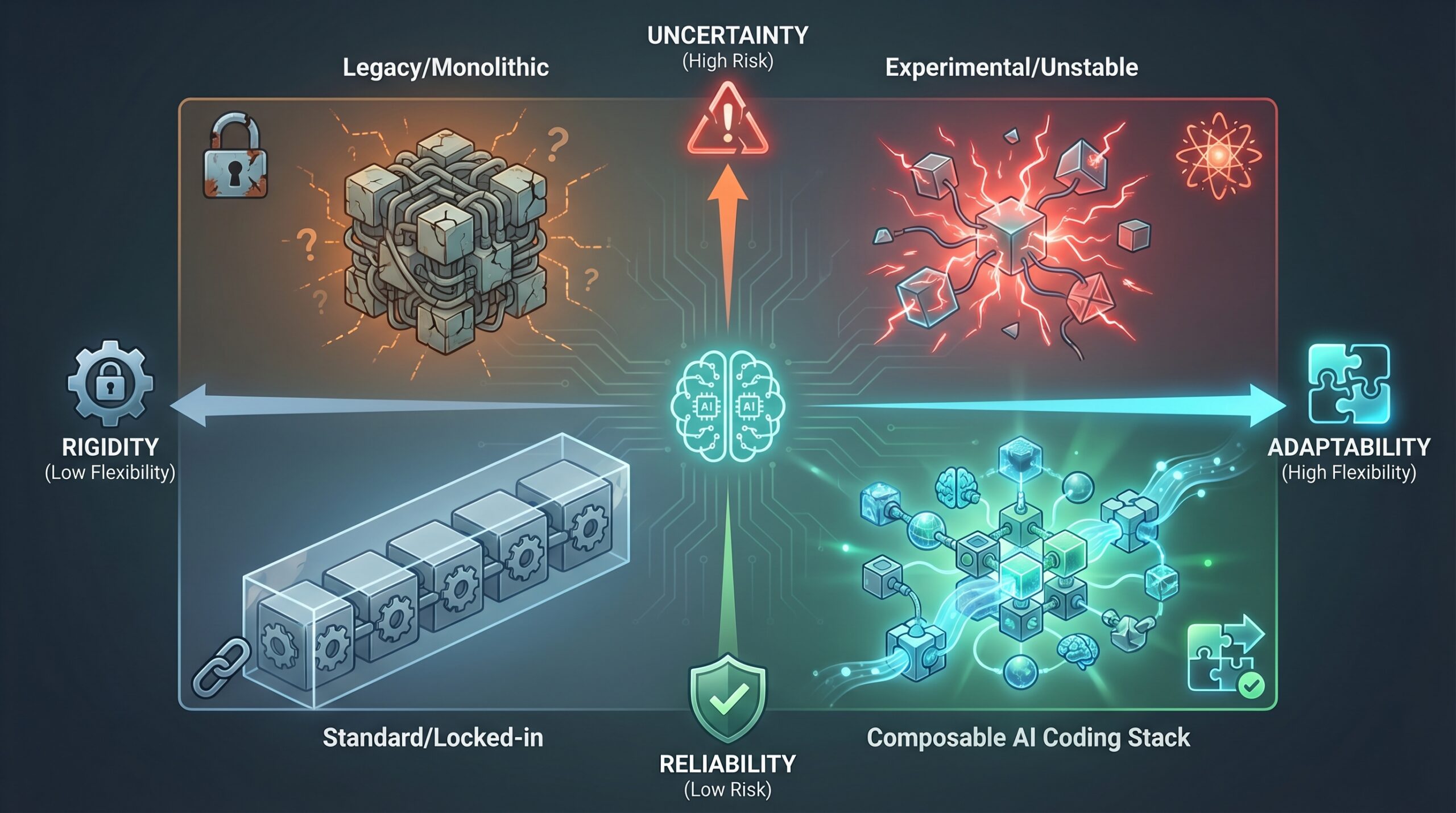
Composable AI vs. Monolithic AI: A Clear Comparison
Understanding the Traditional Monolithic AI Approach
The traditional approach bundles all AI functionality—data loading, preprocessing, feature engineering, model inference, and business logic—into a single, large codebase (e.g., a single Python application using scikit-learn and Flask). This application is built, tested, and deployed as one unit. Updating the model requires redeploying the entire application. Scaling requires scaling the whole monolith, even if only one part is resource-intensive.
The Composable AI Coding Stack Advantage Over Monoliths
Composability delivers agility where monoliths create rigidity. It allows you to adopt new technologies piecemeal, scale bottlenecks precisely, and isolate failures. If a new, more efficient embedding model is released, you deploy it as a new service version and reroute traffic, leaving the rest of your system untouched. This is impossible in a monolith without a risky, full-scale redeployment.
Composable AI Coding Stack Alternatives and Complementary Architectures
- Microservices Architecture: Composable AI is a specialization of microservices for the AI domain. While microservices can be for any business function (e.g., payment service, user service), a composable AI coding stack specifically deals with AI/ML components. All composable AI stacks are built on microservices principles, but not all microservices systems are AI-focused.
- Serverless Functions: These (AWS Lambda, Google Cloud Functions) are an excellent implementation detail for components within a composable stack. They offer extreme scalability and cost-efficiency for stateless, event-driven components (e.g., a data validation function triggered by a new file upload).
- Monorepos: Interestingly, a monorepo (a single repository for multiple projects) can coexist with a composable architecture. It can help manage the code for all your independent components in one place, improving dependency management and cross-component refactoring, while the deployment and runtime remain fully decoupled.
| Feature | Composable AI Coding Stack | Monolithic AI Approach |
|---|---|---|
| Modularity | High. System is built from independent, replaceable components. | Low. Functions are tightly coupled within a single codebase. |
| Reusability | High. Components are designed as shared services. | Low. Code is often duplicated or tightly bound to a specific app. |
| Development Speed (Initial) | Can be slower due to upfront architectural design. | Faster for a simple, single-purpose prototype. |
| Development Speed (Iterative) | Very Fast. New features integrate by adding/swapping components. | Slows dramatically as codebase grows and couples. |
| Scalability | Fine-grained. Scale only the component under load (e.g., the LLM API gateway). | Coarse-grained. Must scale the entire application instance. |
| Maintenance | Easier. Update, patch, or fix components in isolation. | Harder. A change in one library can break unrelated features. |
| Technology Flexibility | High. Use best language/framework for each component (Python for ML, Go for APIs). | Low. Locked into the primary stack’s ecosystem (e.g., Python/PyTorch). |
| Risk of Vendor Lock-in | Low. Components can be replaced with alternatives adhering to the same API contract. | High. The entire app may depend on a specific cloud provider’s ML service. |
| Cost Structure | Variable, pay-per-use for external APIs; optimized infra for internal components. | Often higher long-term due to inefficient resource allocation. |
| Debugging Complexity | Higher. Requires distributed tracing to follow a request across services. | Lower. All logic is in one process, using standard debuggers. |
Tools, Vendors, and Implementation Paths for a Composable AI Coding Stack
Essential Categories of Composable AI Tools
Your toolchain should support the entire lifecycle of independent components.
MLOps & Model Management:
- Experimentation/Tracking: Weights & Biases, MLflow Tracking, DVC.
- Model Registry: MLflow Model Registry, Vertex AI Model Registry, SageMaker Model Registry.
- Model Serving: BentoML (for packaging and deploying models as APIs), Seldon Core (for advanced inference graphs on Kubernetes), Triton Inference Server (NVIDIA, for multi-framework high-performance serving), TorchServe (PyTorch).
- Feature Stores: Feast (open-source), Tecton (managed enterprise), Hopsworks, Vertex AI Feature Store.
Orchestration & Integration:
- Pipeline/Workflow Orchestration: Apache Airflow (mature, but complex), Prefect (modern, Python-native), Kubeflow Pipelines (Kubernetes-native), Dagster (focus on data-aware orchestration).
- Application Orchestration/Workflow Engine: Temporal (excellent for long-running, reliable workflows), Camunda.
- API Management: Kong (open-source API gateway), Apigee (Google Cloud), Amazon API Gateway.
- Event Streaming: Apache Kafka, Confluent Cloud, AWS EventBridge, Google Pub/Sub.
Data & Infrastructure:
- Vector Databases: Pinecone (managed), Weaviate (open-source), Qdrant, Milvus.
- Containerization & Orchestration: Docker, Kubernetes (essential for production), Helm (for package management).
- Serverless Platforms: AWS Lambda, Google Cloud Run, Azure Container Apps (for hosting lightweight components).
- Monitoring & Observability: Prometheus/ Grafana (metrics), ELK Stack/Loki (logs), Jaeger/ OpenTelemetry (distributed tracing).
AI/ML Services (as Components):
- Cloud AI APIs: Google Vertex AI (Unified ML platform), AWS SageMaker (JumpStart, Canvas), Azure Machine Learning and Azure AI Services (Vision, Language, Speech).
- LLM/Foundation Model APIs: OpenAI API (GPT-4, GPT-4o), Anthropic Claude API, Google Gemini API, Cohere API, Meta AI API (Llama).
- Specialized AI Services: Hugging Face Inference Endpoints, Replicate (for running open-source models), Roboflow (computer vision).
Core Tool Categories for a Composable AI Coding Stack
- MLOps & Model Management: Experimentation Tracking (W&B), Model Registries (MLflow), Model Serving (BentoML, Seldon Core), Feature Stores (Feast)
- Orchestration & Integration: Workflow Orchestrators (Airflow, Prefect), Application Orchestration (Temporal), API Management (Kong), Event Streaming (Kafka)
- Data & Infrastructure: Vector Databases (Pinecone, Weaviate), Containerization (Docker, Kubernetes), Serverless (AWS Lambda), Monitoring (Prometheus/Grafana)
- AI/ML Services (as Components): Cloud AI APIs (Vertex AI, AWS SageMaker), LLM/Foundation APIs (OpenAI, Anthropic), Specialized AI Services (Hugging Face, Replicate)
Key Vendors in the Composable AI Ecosystem
Major players are building platforms that either embody or facilitate composability:
- Hyperscalers (Full-Stack Platforms): Google Cloud (Vertex AI), Amazon Web Services (Sagemaker, Bedrock), Microsoft Azure (Azure Machine Learning, Azure AI). They provide integrated suites where many tools (registries, feature stores, pipelines) are designed to work together, reducing integration friction.
- Enterprise AI/Data Platforms: Databricks (with MLflow, Feature Store, and serving) offers a unified analytics and AI platform that strongly supports component-based workflows. Snowflake (with Snowpark ML) is expanding into the AI feature and model space.
- Model Hubs & Communities: Hugging Face is the de facto marketplace and registry for models, datasets, and spaces (demo apps), making it a primary source for components.
- Specialist MLOps Vendors: Weights & Biases (experimentation, model registry), Tecton (feature platform), Domino Data Lab (enterprise ML platform).
Choosing Your Composable AI Implementation Strategy
Your path depends on team size, existing infrastructure, and strategic goals.
- Start with Orchestration, Not Components: Begin by setting up a robust workflow orchestrator (Prefect or Airflow) and a simple API gateway. This establishes the “composition” backbone before you decompose your monolith.
- Adopt an API-First Mentality for All New Models: Any new model developed by the data science team must be packaged as a containerized API (using BentoML or Seldon Core) from day one, not as a Python script or notebook.
- Containerize Everything: Docker is non-negotiable. It ensures each component runs in a predictable environment, with its own dependencies, making them truly independent.
- Leverage Managed Services for Undifferentiated Heavy Lifting: Don’t build your own vector database or speech-to-text service initially. Use Pinecone and Azure Speech Services. This gets you viable components immediately and defines the API contracts you must meet if you ever decide to build in-house.
- Implement a “Strangler Fig” Pattern for Legacy Systems: Gradually decompose a monolithic AI application. Identify a single, bounded function (e.g., “calculate user churn score”), extract it into a microservice, and reroute calls from the monolith to the new service. Repeat piece by piece.
Costs, ROI, and Monetization Upside of a Composable AI Coding Stack
Initial Investment and Ongoing Costs for Composable AI
- Architecture & Design: Upfront cost in developer/architect time is significant. Designing clear domain boundaries, API contracts, and deployment patterns requires skilled personnel and planning cycles.
- Infrastructure Complexity: Operating a distributed system has inherent costs. You need a Kubernetes cluster (or managed K8s like GKE/EKS), API gateway licenses, and potentially more robust networking (service meshes like Istio). This overhead is higher than running a single Flask app on a VM.
- Operational Overhead: More moving parts mean more to monitor. Costs for observability tools (e.g., Datadog, Grafana Cloud) and the personnel to manage them increase.
- External API Costs: Using components like OpenAI GPT-4 API incurs direct, usage-based costs. These can be substantial at scale and must be monitored and optimized.
Calculating the Return on Investment (ROI) of Composable AI
The ROI becomes compelling when evaluated over a 12-24 month horizon:
- Accelerated Feature Velocity: If a new AI feature takes 3 months monolithically but 3 weeks composably, you generate revenue or savings 9 weeks earlier. Multiply this across multiple features.
- Reduced “Change Cost”: The cost of swapping a model or updating a library in a monolith involves regression testing the entire application. In a composable stack, it’s confined to one component. This can reduce maintenance costs by 40-60% for mature systems.
- Infrastructure Efficiency: Scaling components independently avoids over-provisioning. You don’t pay for 16GB RAM VMs to host a lightweight API gateway when it only needs 2GB.
- Avoided Vendor Lock-in & Technical Debt: The ability to replace a costly or underperforming AI service provider protects you from price hikes or service degradation. This optionality has significant strategic financial value.
Monetization Opportunities with a Composable AI Stack
- New Product Launches: The ability to quickly assemble AI capabilities means you can prototype and test new AI-powered products faster, entering new markets or creating new revenue streams. For instance, creating AI-powered trading bots or AI automation scripts can be significantly expedited.
- AI-as-a-Service (Internal or External): Well-designed components can be offered to other business units or even external partners as APIs, turning cost centers into potential profit centers.
- Process Optimization: Automating complex business processes (e.g., insurance claim adjudication, contract review) by composing document AI, rules engines, and LLM components leads to direct labor cost savings and error reduction.
- Enhanced Customer Experience: Personalization and intelligent support (as described earlier) directly increase customer lifetime value (CLV) and retention, impacting top-line revenue.
Risks, Pitfalls, and Myths vs. Facts of Composable AI
Potential Risks in Adopting a Composable AI Coding Stack
- Distributed System Complexity: Debugging a failing request that passes through 5 different services, each with its own logs, is an order of magnitude harder than debugging a monolith. Without distributed tracing, it’s nearly impossible.
- Data Governance Nightmares: Ensuring data privacy (PII), regulatory compliance (GDPR, HIPAA), and consistency as data flows across multiple components—some internal, some third-party—is a major challenge. A data contract violation in one component can corrupt the entire pipeline.
- Network Latency and Reliability: Every API call is a network hop, introducing latency and a point of failure. The system’s overall reliability is the product of each component’s reliability. If 5 components each have 99.9% uptime, the chain’s theoretical uptime is 99.5%.
- Security Attack Surface Expansion: Every API endpoint is a potential entry point. You must secure service-to-service communication (mTLS), manage secrets for API keys, and audit access consistently across all components. Keeping up with AI security threats is paramount.
- Consistent Monitoring and Alerting: Getting a unified view of the health, performance, and cost of the entire composed workflow requires integrating metrics from diverse sources.
Common Pitfalls to Avoid in Composable AI Implementation
- Pitfall 1: Vague or Unversioned APIs. Creating components without strict, documented, and versioned contracts leads to integration hell. Solution: Use OpenAPI/Swagger from day one and enforce semantic versioning (
/v1/,/v2/). - Pitfall 2: Ignoring Idempotency and Retry Logic. In a distributed system, network calls fail. If your “charge customer” component is called twice because of a retry, you have a critical problem. Solution: Design key operations to be idempotent (using unique idempotency keys) and implement intelligent retry with backoff in your orchestrator.
- Pitfall 3: Tight Coupling via Data Schemas. While components are independent, if the data schema expected by one component is extremely complex and tailored to a specific predecessor, you’ve created coupling. Solution: Use canonical, generalized data models between layers.
- Pitfall 4: Neglecting Component Ownership. In a “everyone’s component” environment, no one maintains them. Solution: Assign clear product/engineering ownership for each component, with defined SLAs (e.g., latency, uptime).
- Pitfall 5: Building Components That Are Too Fine-Grained. The overhead of network calls for a function that adds two numbers is absurd. Solution: Components should represent a meaningful business or technical capability, not a single function.
What Most People Get Wrong About Composable AI
- Myth: “Composable AI is plug-and-play. We’ll just wire APIs together and be done.”
Fact: It requires deep architectural discipline. The “plugs” (APIs) need to be designed, the “wiring” (orchestration) needs to be robust, and the entire system needs observability. The initial setup is complex. - Myth: “It’s always cheaper than building ourselves.”
Fact: It has a different cost profile. Initial costs are higher (design, infrastructure). The long-term ROI comes from agility, reusability, and reduced lock-in, not from lower day-one bills. Relying solely on expensive external APIs can also become costly. - Myth: “This eliminates the need for deep AI/ML expertise.”
Fact: It shifts and expands the required expertise. You still need data scientists to fine-tune models and MLEs to build robust components. Now you also need software engineers skilled in distributed systems, API design, and orchestration to compose them. - Myth: “It’s only for large tech companies.”
Fact: Cloud providers have democratized the necessary infrastructure. A startup can begin with a serverless orchestrator (Prefect Cloud), two Lambda functions as components, and the OpenAI API, achieving a composable architecture from day one with minimal ops burden.
Frequently Asked Questions About the Composable AI Coding Stack
What is the primary benefit of a composable AI coding stack?
The primary benefit is strategic agility. It allows your organization to adapt its AI capabilities at the pace of AI innovation itself. You can replace underperforming models, integrate new AI services, and scale specific functions independently, without the massive re-engineering projects required by monolithic systems. This directly translates to faster time-to-market for AI features and resilience against technological obsolescence.
How does a composable AI stack differ from traditional AI development?
Traditional development often produces a single, tightly integrated application (a monolith) where the data pipeline, model logic, and application code are interwoven. A composable AI coding stack decomposes this into standalone services (components) that communicate via APIs. The focus shifts from writing cohesive code within one repository to designing clear contracts and orchestrating interactions between independent, possibly heterogenous, services.
What kind of organizations benefit most from a composable AI coding stack?
Organizations that benefit most are those facing dynamic AI needs: (1) Fast-growing tech companies that need to iterate rapidly on AI features, (2) Enterprises with multiple, diverse AI use cases (e.g., fraud, recommendation, chatbots) who want to share components across teams, (3) Companies reliant on external AI innovations who need to easily swap between different model providers or APIs, and (4) Teams with established MLOps practices looking to increase efficiency and reduce technical debt.
What are the common challenges when implementing a composable AI stack?
The top challenges are managing increased operational complexity (monitoring, debugging), ensuring consistent data governance and security across a network of services, avoiding the pitfall of creating distributed monoliths (components that are still tightly coupled through data or logic), and the cultural shift required for teams to think in terms of service ownership and API contracts rather than monolithic code ownership.
Can existing AI models be integrated into a composable AI coding stack?
Absolutely. This is a common and recommended migration path. Existing models can be “wrapped” by creating a lightweight API service around them (using frameworks like FastAPI or BentoML) and then containerized with Docker. This turns your legacy model into a modern, composable component. The key is to define a clean, well-documented input/output interface for the new service, effectively hiding the legacy implementation details.
Glossary of Composable AI Terminology
Key Terms in the Composable AI Ecosystem
- API-First Design: A development approach where the interface (API) for a component is designed and agreed upon before any implementation code is written. This ensures interoperability from the start.
- Data Contract: A formal specification of the structure, semantics, and quality expectations of data exchanged between components. It can be enforced using schema validation tools.
- Feature Store: A dedicated data system for managing, storing, and serving pre-computed features (model inputs) consistently across training and real-time inference environments. Key for composable AI to ensure models get consistent data.
- Inference Service: A deployed, containerized service whose sole purpose is to run a trained machine learning model (perform inference) on incoming requests via an API.
- Model Registry: A centralized repository to track, version, and manage the lifecycle of machine learning models. It acts as the source of truth for which model version is currently deployed in a given inference service.
- Orchestration: The automated coordination and management of multiple independent components or services to execute a broader workflow or business process. Tools like Apache Airflow and Temporal are orchestrators.
- Vector Database: A specialized database optimized for storing and retrieving high-dimensional vector embeddings (arrays of numbers). It enables fast similarity search, which is fundamental for Retrieval-Augmented Generation (RAG) and other semantic AI components.
References and Further Reading on Composable AI
Cited Sources and Recommended Resources for Composable AI Coding Stacks
- Engineering Blogs:
- Uber Engineering, “The Path to a Composable ML Platform” (A classic case study on decomposing monoliths).
- Netflix Tech Blog, numerous articles on personalization and microservices.
- DoorDash Engineering, “Building a Composable ML Platform with Feast and Airflow” (Practical integration example).
- Industry Reports:
- Andreessen Horowitz, “The New Business of AI (and How It’s Different)” (Discusses the shift to AI-as-a-service and composability).
- McKinsey & Company, “The state of AI in 2025” (Annual report highlighting trends in AI adoption and architecture).
- Foundational Concepts:
- Martin Fowler’s articles on Microservices and the Strangler Fig Pattern.
- The Rise of the MLOps Ecosystem (ODSC, Towards Data Science).
- Technology Documentation:
- Prefect Documentation (Orchestration concepts).
- BentoML Documentation (Model serving and packaging).
- Hugging Face Blog (On model deployment and integration).
Composable AI Coding Stack: The Complete Guide to Building Flexible AI Systems in 2026 Framework 3
- Signal: What changed and why this matters now.
- Decision framework: Compare options by cost, risk, and implementation effort.
- Execution checklist: Concrete next step and measurable outcome.


