
DeepSeek AI has released its V4 series open-source models (DeepSeek-V4-Pro and DeepSeek-V4-Flash) under the MIT License, featuring a 1-million token context window and performance rivaling leading closed-source models. This development significantly impacts operators by offering cost sovereignty, performance parity (especially in math and agentic coding), and geopolitical optionality through Huawei Ascend chip optimization. Operators should prioritize rigorous in-house validation, understand the true cost of self-hosting vs. proprietary APIs, and proactively mitigate risks associated with adoption, while leveraging the clear potential for new product and research avenues.
DeepSeek AI’s newly released V4 series open-source models, including DeepSeek-V4-Pro and DeepSeek-V4-Flash, are now available under the permissive MIT License. These models feature a groundbreaking 1-million token context window and demonstrate performance competitive with, and in some areas exceeding, proprietary models like Google’s Gemini-Pro-3.1, particularly in mathematics and agentic coding. This provides operators with significant advantages in cost control, data privacy, and the ability to process extremely long documents or codebases within a single prompt, while also offering strategic hardware diversification through optimization for Huawei Ascend chips.
The DeepSeek AI News Flood: V4 Series Release
The most significant development is the preview release of the DeepSeek-V4 series. On April 24, 2026, DeepSeek made available its flagship model, DeepSeek-V4-Pro, and its smaller, faster sibling, DeepSeek-V4-Flash.
Both models are released under the permissive MIT License, granting extensive commercial usage rights. The headline-grabbing specs include a 1-million token context window—making processing book-length documents or entire code repositories routine—and performance claims that directly challenge proprietary giants. This release is not an incremental update; it’s a strategic escalation in the open-source AI arms race.
Why the DeepSeek-V4 Release Matters for Operators
For operators—CTOs, AI engineers, product managers, and researchers—this release matters for three concrete reasons. First, cost sovereignty: self-hosting DeepSeek models decouples you from volatile and opaque API pricing from closed-source providers, offering long-term cost predictability. Second, performance parity: DeepSeek-V4-Pro’s benchmark results, particularly in mathematics (95.2 on HMMT 2026) and agentic coding, mean you no longer need to sacrifice capability to gain open-source flexibility. Third, geopolitical and supply chain optionality: the model’s optimization for Huawei’s Ascend chips provides a viable hardware alternative to NVIDIA for operators facing export restrictions or seeking competitive pricing in specific regions.
DeepSeek AI: The Company Behind the Models
DeepSeek AI is a research lab based in Hangzhou, China. It gained initial recognition in January 2025 with the release of its DeepSeek-R1 reasoning model, which demonstrated that high performance could be achieved with relatively limited computational resources—a theme of efficiency that continues with the V4 series.
Unlike many AI labs that keep their best models closed, DeepSeek has committed to a strong open-source strategy, positioning itself as a key driver of China’s influence in the global AI ecosystem. Its close collaboration with Huawei on chip optimization is a clear signal of this strategic alignment toward technological self-sufficiency.
DeepSeek Model Deep Dive: Capabilities and Architecture
To understand the practical impact, you must understand the architectural specifics of the DeepSeek open source model family. DeepSeek uses a Mixture-of-Experts (MoE) architecture, which is crucial for managing its immense parameter count efficiently. For DeepSeek-V4-Pro, the model has 1.6 trillion total parameters, but only 49 billion activated parameters per forward pass.
This means the model has vast knowledge capacity, but inference costs are governed by the activated subset, not the total. This makes it more efficient than a dense model of similar total size. DeepSeek-V4-Flash follows the same principle with 284 billion total and 13 billion activated parameters.
The 1-Million Token Context Window: A Game Changer
The 1-million token context window is perhaps the most immediately usable feature. In practice, this means:
- You can feed the model an entire software project (e.g., a React codebase with all dependencies) and ask for a systematic refactor.
- Legal, financial, or research teams can analyze multiple lengthy documents (contracts, annual reports, research papers) in a single prompt without complex chunking and information loss.
- AI agents can maintain extremely long, coherent conversation histories, remembering context from hundreds of prior interactions.
This capability moves “long context” from a specialized feature to a default expectation, opening up new product and research avenues. The DeepSeek-V4-Pro is also available on platforms like Together AI with its 1M context.
Benchmark Performance: Where DeepSeek Excels and Lags
DeepSeek’s own benchmarks tell a compelling story. For world knowledge, they claim DeepSeek-V4-Pro trails only Google’s closed-source Gemini-Pro-3.1. In mathematics, it outperforms most closed models with scores of 95.2 on HMMT 2026 and 89.8 on IMOAnswerBench. Most critically for developers, DeepSeek claims “world class” agentic coding capability among open-source models.
However, operators must treat these claims as strong signals, not guarantees. Real-world performance on your specific tasks—customer support transcripts, domain-specific legal text, proprietary code conventions—will vary and requires rigorous in-house validation.
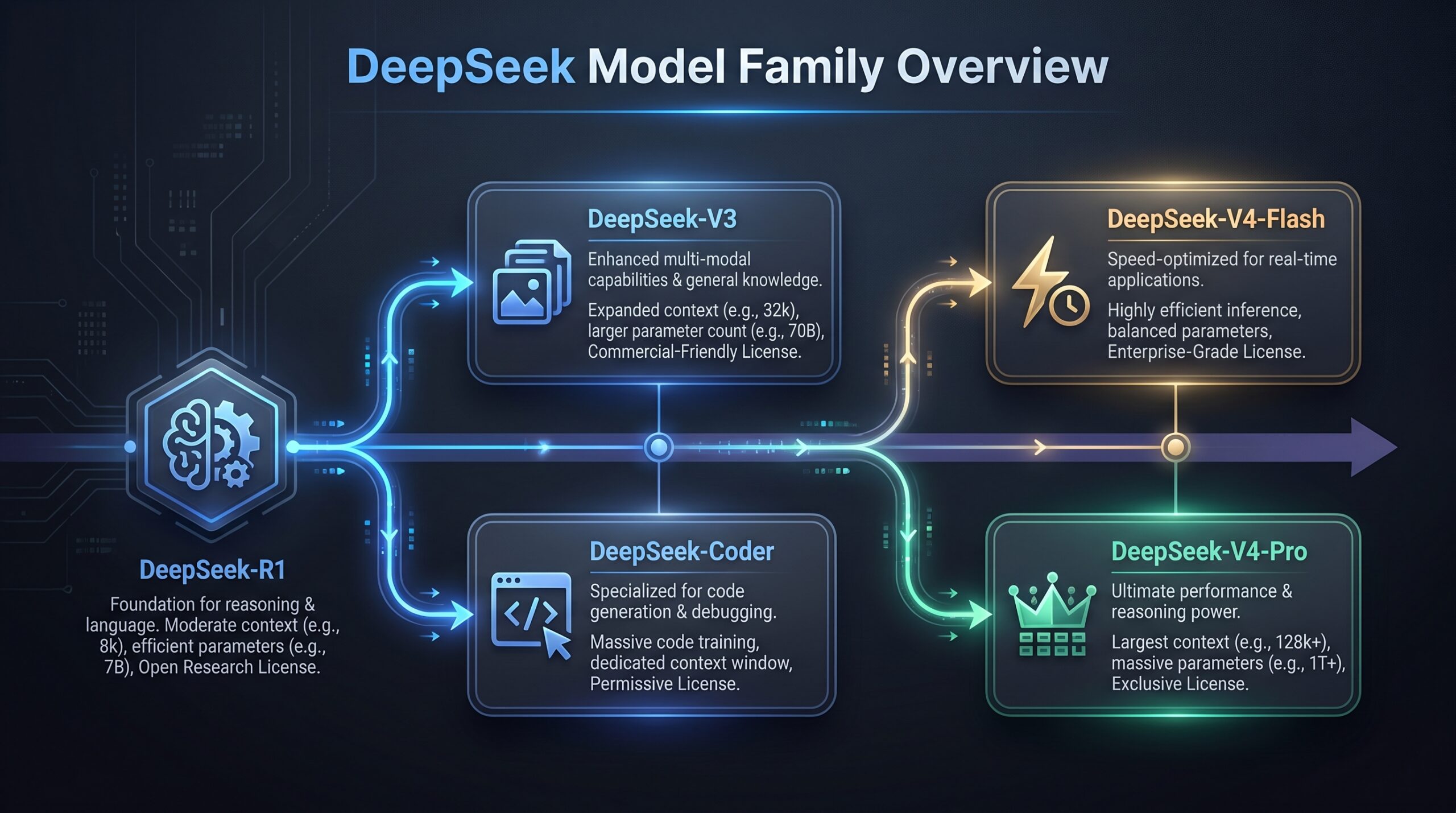
DeepSeek Model Comparison: V3, V4 Pro, and Coder
| Feature | DeepSeek-V3 (Base/Chat) | DeepSeek-V4 Pro | DeepSeek-Coder |
|---|---|---|---|
| Core Purpose | General-purpose language tasks, conversation. | Frontier general intelligence, high-stakes reasoning, complex tasks. | Specialized for code generation, explanation, and debugging. Note: V4 series claims integrated world-class coding. |
| Architecture | Dense or earlier MoE architecture. | Advanced Mixture-of-Experts (1.6T total, 49B active). | Architecture optimized for code syntax and logic. |
| Context Window | Typically 32k to 128k tokens. | 1 Million Tokens. | Varies by version; check for latest. |
| Key Strength | Established, well-tested open-source model. | Benchmark-leading performance in math, coding, and knowledge; massive context. | Domain-specific precision for software development. |
| Open-Source Status | Open source (verify specific license). | MIT License (confirmed for V4 preview). | Open source (verify specific license). |
| Best For Operators Who… | Need a proven, capable model for standard NLP tasks without the latest frontier features. | Require state-of-the-art performance, especially for math/reasoning, or must process extremely long documents. | Are building developer tools, AI pair programmers, or automated code review systems. |
DeepSeek vs. Leading Open-Source LLMs (Llama 3, Mistral)
How does the DeepSeek open source model stack up against its main rivals? This comparison is critical for choosing your foundational model.
| Attribute | DeepSeek-V4 Pro | Meta Llama 3 70B | Mistral Large 2 (Mistral AI’s flagship) |
|---|---|---|---|
| Release Philosophy | Push the frontier of open-source capability; compete directly with closed models. | Democratize safe and capable AI; broad ecosystem play. | Deliver high-performance models with a European focus, blending open and closed strategies. |
| Scale & Architecture | 1.6T MoE (49B active). Largest in open-source. | 70B Dense. | Likely a large MoE or dense model (exact specs often proprietary). |
| Context Window | 1 Million Tokens (standout feature). | 8k (standard), 128k+ with extrapolation. | Typically 128k-256k range. |
| Benchmark Standing | Claims leadership in math (HMMT, IMO) and coding among open-source. | Strong all-rounder, excellent for instruction following. | Highly competitive in reasoning and multilingual tasks. |
| Licensing | MIT License (highly permissive). | Llama 3 Community License (also permissive for most use). | Often Apache 2.0 or proprietary for largest models. |
| Hardware Ecosystem | Explicitly optimized for Huawei Ascend chips, plus standard GPU support. | Primarily NVIDIA GPU ecosystem. | Primarily NVIDIA GPU ecosystem. |
| Strategic Differentiator | Chinese tech stack alignment, extreme scale, and context. | Massive community, tooling, and safety focus. | Strong European regulatory alignment and multilingual prowess. |
When to Choose DeepSeek Over Llama or Mistral
Choose a DeepSeek open source model if:
- Your application demands the 1-million token context for processing vast documents or datasets.
- You are operating in or selling to markets where Chinese tech stack compatibility (e.g., Huawei Ascend chips) is an advantage or a requirement.
- Your core metric is peak performance in mathematical reasoning or agentic coding, based on your own validation against the claimed benchmarks.
- You want to build on the most recent architectural frontier in the open-source space and are prepared to handle the accompanying complexity.
Choose Llama 3 if you prioritize a massive community, extensive fine-tuning guides, proven safety features, and robust tooling support. Choose Mistral Large if your focus is on European languages, compliance with EU regulations, or you value their specific blend of open and proprietary model offerings. For more on advanced model capabilities, explore how LLMs Implement Agent-Based Models.
Geo-Political and Strategic Implications: The DeepSeek-V4 release, especially its Huawei Ascend optimization, signals a growing diversification in the global AI hardware landscape. This offers not just technical alternatives but also strategic options for countries and enterprises looking to reduce reliance on single-source suppliers or align with specific technological ecosystems. Operators should consider these broader implications in their long-term infrastructure planning.
The Real Cost: DeepSeek Self-Hosting vs. Proprietary APIs
The financial case for open-source hinges on total cost of ownership. While self-hosting has upfront costs, it eliminates per-token API fees and can be more predictable. This is a critical consideration for any AI-powered venture, especially when looking at broader patterns like the AI cost surge at Meta.
| Cost Factor | DeepSeek Self-Hosting (Example: V4-Pro) | Proprietary API (Example: GPT-4-128k) |
|---|---|---|
| Upfront Model Cost | $0. Model weights are free under MIT License. | $0. No model acquisition cost. |
| Primary Cost Driver | GPU Infrastructure. Running a model of this size requires multiple high-end GPUs (e.g., H100/A100 clusters or Ascend 910 systems) for acceptable latency. | Per-Token Usage Fees. Costs scale directly with every input and output token, creating variable, unpredictable expenses. |
| Inference Cost (Example) | High fixed cost for hardware/cloud instances. E.g., ~$50-$200/hr for a cloud instance capable of running V4-Pro at reasonable speed. Cost per query decreases with higher utilization. | Variable cost. E.g., ~$0.03 per 1K output tokens for GPT-4-128k context. High-volume applications generate massive, ongoing bills. |
| Context Window Advantage | 1M tokens at a fixed cost. Process enormous documents without exponentially increasing fees. | Costs scale linearly with context length. Filling a 128k context is expensive; a 1M context would be prohibitive. |
| Data Privacy & Control | Full control. Data never leaves your infrastructure. Essential for regulated industries (healthcare, finance). | Data is sent to a third-party provider, requiring careful review of their data processing agreements. |
| Best For | High-throughput, predictable workloads; data-sensitive applications; long-context use cases; organizations with existing GPU infrastructure. | Low-volume, prototyping, or applications where engineering overhead must be minimized. |
Case Study 1: AI-Powered Legal Document Analysis Firm
A firm analyzing mergers & acquisitions documents previously used a closed-source API. They processed thousands of pages monthly. Their API costs were spiraling, especially for complex cross-document analysis requiring large context. They switched to a self-hosted DeepSeek-V4-Pro instance on a private cloud. The move:
- Year 1 Cost: $250k for GPU infrastructure setup and engineering.
- Previous Annual API Cost: ~$180k and growing.
- Result: By year two, with infrastructure depreciated, their marginal cost per document analysis dropped by over 70%. The 1M token window allowed them to analyze entire deal bundles at once, improving analysis quality and enabling new product features.

Getting Started: Accessing and Deploying DeepSeek Models
Where to Find the DeepSeek Open Source Model
The primary source for the official DeepSeek open source model releases is GitHub (github.com/deepseek-ai). Here you will find the model weights, inference code, and release notes. Hugging Face Hub (huggingface.co/deepseek-ai) is the secondary hub for easy download and integration into popular ML frameworks like Transformers. Always verify you are downloading from these official repositories to ensure model integrity.
Self-Hosting Implementation Checklist
Deploying a model like DeepSeek-V4-Pro is a serious engineering undertaking. Use this checklist to structure your project.
- Infrastructure Provisioning:
- Determine target hardware: NVIDIA (H100, A100) or Huawei Ascend 910.
- Provision cloud instances (AWS p5/p4, Azure ND/NC, Alibaba Cloud) or on-premises servers with sufficient VRAM (>160GB for V4-Pro in FP16).
- Set up networking and security groups for inference endpoints.
- Model Setup & Optimization:
- Download official weights from GitHub/Hugging Face.
- Choose an inference server: vLLM, TGI (Text Generation Inference), or DeepSeek’s own serving stack if provided.
- Apply quantization (e.g., to GPTQ/AWQ or FP8) to reduce memory footprint and increase speed. Test performance degradation.
- Implement continuous batching to handle multiple requests efficiently.
- Deployment & MLOps:
- Containerize the model and server using Docker.
- Deploy using Kubernetes or a managed service (e.g., SageMaker, Azure ML) for scaling and resilience.
- Set up monitoring for latency, throughput, GPU utilization, and error rates (Prometheus/Grafana).
- Implement a load balancer and API gateway (e.g., NGINX) in front of your model servers.
- Integration & Testing:
- Develop a client library or adapter to match your existing application’s expected API format.
- Run comprehensive load testing to establish performance baselines and scaling thresholds.
- Conduct A/B testing against your previous model/API to validate quality and cost improvements.
Using the DeepSeek API (The Fast Path)
For teams not ready for self-hosting, DeepSeek offers its own proprietary API, providing instant access to the V4 models. This is ideal for:
- Rapid prototyping and validating use cases.
- Low-volume production applications where engineering infrastructure costs outweigh API fees.
- Complementing a self-hosted setup for overflow traffic or fallback.
Check DeepSeek’s official website for the latest pricing, rate limits, and available regions. Be aware that using their API reintroduces the data privacy and long-term cost variability concerns inherent to any third-party service, similar to considerations for OpenAI Models on Amazon Bedrock.
Risk Mitigation Checklist for DeepSeek Adoption
Adopting a cutting-edge DeepSeek open source model comes with risks. Proactively manage them with this checklist.
- License Verification: Confirm the exact license (MIT for V4) for your chosen model version. Review terms for commercial use, modification, and redistribution. Do not rely on hearsay from forums.
- Performance Validation: Do not rely solely on published benchmarks. Create a custom evaluation dataset representative of your production tasks. Measure key metrics (accuracy, latency, cost per task) against incumbent models.
- Supply Chain Diversification: If considering Huawei Ascend hardware, assess the geopolitical and logistical risks for your organization. Have a fallback plan using NVIDIA GPUs, potentially looking into NVIDIA AI models for quantum systems.
- Expertise Audit: Honestly assess your team’s MLOps capabilities. Hiring or training for skills in distributed model serving, GPU optimization, and LLM fine-tuning may be necessary.
- Cost Projection Modeling: Build a detailed 3-year Total Cost of Ownership (TCO) model comparing self-hosting (hardware, power, engineering) versus API costs. Factor in expected growth in query volume.
- Vendor Lock-in Mitigation: Architect your application with a model abstraction layer. This allows you to swap the underlying model (DeepSeek, Llama, API) with minimal code changes, protecting you from model deprecation or licensing changes.
- Security & Compliance Review: For self-hosting, ensure your infrastructure meets internal security standards. For API use, meticulously review DeepSeek’s data processing agreement for compliance with regulations like GDPR or CCPA. For general guidance, refer to AI Security Questions for Tech Giants.
DeepSeek Adoption Risk Mitigation Framework
- Technical Risks:
– Complexity of self-hosting,
– Benchmark vs. real-world performance gap,
– Fast model deprecation. - Operational Risks:
– Talent gap for MLOps/GPU optimization,
– Scaling challenges,
– Integration overhead. - Strategic Risks:
– Geopolitical supply chain issues (Ascend chips),
– Vendor lock-in without abstraction,
– Licensing misunderstanding. - Financial Risks:
– Underestimated TCO for self-hosting,
– Unpredictable API costs at scale. - Mitigation Strategies:
– Custom evaluation,
– Model abstraction,
– Diversified hardware strategy,
– Detailed TCO modeling,
– Continuous team upskilling.
A proactive, multi-faceted approach transforms potential DeepSeek adoption challenges into managed strategic initiatives.
Case Study 2: Global E-commerce Platform’s Chatbot Upgrade
A platform with customers worldwide needed a chatbot that could handle complex, multi-question support tickets and understand nuanced product queries. Their old model struggled with long context and reasoning. They piloted DeepSeek-V4-Pro via API for the EU region (due to data residency concerns, they used a regional API endpoint where available) and self-hosted it in their US and Asia data centers.
With DeepSeek, they were finally able to leverage agentic AI to enhance customer service, drawing on insights from articles discussing how AI Agents for Financial Markets are implemented, and the broader context of NVIDIA Dynamo’s optimization for Agentic AI Inference.
The Process:
- They used the API for a 2-month pilot, A/B testing against the old model on 10% of traffic. DeepSeek reduced escalation to human agents by 15%.
- For US/Asia deployment, they followed the self-hosting checklist, using quantized models on their existing GPU clusters to control costs.
- They implemented a model router that could send requests to either the self-hosted instances or the API fallback based on latency and health checks.
The Outcome: Improved customer satisfaction scores, reduced average handling time, and a 40% lower inference cost in self-hosted regions compared to their previous closed-source API provider.
The Strategic Future of DeepSeek and Open Source AI
DeepSeek’s trajectory points to a future where the most capable AI models are open source. The V4 release pressures other players (Meta, Mistral, Google) to open more advanced models or risk losing developer mindshare. The Huawei collaboration is a bellwether for fragmentation in the AI hardware stack, offering an alternative to the NVIDIA/CUDA hegemony. For operators, this means more choice, but also more complexity in navigating competing ecosystems.
The push towards Artificial General Intelligence (AGI) is explicit in DeepSeek’s communications. While AGI remains a contested and distant goal, DeepSeek’s benchmarking against broad human knowledge and reasoning tasks indicates their models are being designed as general-purpose reasoning engines, not narrow tools. This aligns with the operator trend of using a single, powerful foundation model for a wide array of tasks rather than maintaining a fleet of specialized small models.
Key Takeaways on DeepSeek Open Source Models
- Game-Changing Context: The 1-million token context window in DeepSeek-V4-Pro enables unprecedented document and codebase processing in a single pass.
- Performance Parity: DeepSeek-V4-Pro challenges closed-source leaders in benchmarks, especially in math and agentic coding.
- Cost Sovereignty: Self-hosting offers predictable long-term costs and eliminates per-token API fees, providing greater financial control.
- Strategic Diversification: Optimization for Huawei Ascend chips introduces a vital alternative in the hardware supply chain.
- MIT License: The highly permissive MIT license allows extensive commercial use, modification, and distribution.
- Rigorous Validation Essential: Operators must conduct in-house evaluation against custom datasets, as published benchmarks are indicative, not definitive.
- Self-Hosting vs. API: Evaluate the TCO, data privacy needs, and engineering overhead to choose the right deployment strategy.
- Proactive Risk Management: Address licensing, geopolitical, performance, and talent risks with a structured approach.
DeepSeek’s V4 series marks a significant shift, demanding immediate attention and strategic evaluation from any organization leveraging or building with advanced AI.
FAQ
Q: Is DeepSeek-V4 truly open source?
A: Yes, as of its preview release on April 24, 2026, the DeepSeek-V4 series (Pro and Flash) is released under the MIT License. This is a highly permissive license that allows free commercial use, modification, and distribution. Always verify the license in the official repository for the specific model version you download.
Q: What hardware do I need to run DeepSeek-V4-Pro myself?
A: You need significant GPU resources. To run the full, unquantized DeepSeek-V4-Pro model, you will likely need multiple high-end GPUs (e.g., 4-8x NVIDIA H100 or their equivalent) with a large aggregate VRAM (>160GB). Quantization can reduce this requirement. Notably, the model is also optimized for Huawei Ascend 910 chips, providing a major alternative hardware path.
Q: How does DeepSeek’s performance compare to GPT-4?
A: DeepSeek claims its V4-Pro model is competitive with leading closed-source models. In specific benchmarks like mathematics (HMMT 2026, IMOAnswerBench), it reportedly outperforms most closed models. For general reasoning and coding, it claims to be world-class among open-source models. However, comprehensive, independent head-to-head evaluations on diverse real-world tasks are needed. You must validate performance on your own data. This is particularly relevant given recent shifts like GitHub Copilot deprecating older GPT models.
Q: Can I fine-tune DeepSeek models for my specific task?
A: Yes, the open-source nature of the models means you can fine-tune them on your proprietary data. This requires the technical expertise and computational resources to perform parameter-efficient fine-tuning (PEFT) like LoRA or full fine-tuning. The permissive MIT license allows you to use and distribute your fine-tuned versions for commercial purposes.
Q: What are the main risks of relying on DeepSeek models?
A: Key risks include: 1) High self-hosting complexity and cost, 2) Geopolitical considerations due to its Chinese origin and Huawei ties, 3) Rapid model iteration potentially making your deployed version obsolete quickly, and 4) The need for in-house validation of benchmark claims. A thorough risk assessment is essential before building a critical system on it.
What to Do Next: Your Action Plan
The DeepSeek open source model release is a live opportunity. Here is your immediate action plan:
- Week 1: Assess & Learn.
- Clone the official GitHub repo and review the release notes and license.
- Run a small, non-critical proof-of-concept using the DeepSeek API. Test the 1M token context with a sample of your long-form data.
- Assemble a cross-functional team (engineering, product, legal) to discuss the opportunity and risks.
- Week 2-4: Validate & Plan.
- Build your custom evaluation benchmark. Quantify DeepSeek-V4’s performance on 5-10 of your core tasks against your current solution.
- Develop a preliminary TCO model. Estimate costs for both API and self-hosting scenarios over 24 months.
- Draft an adoption roadmap if the results are positive. Identify a low-risk, high-impact first project for implementation.
- Month 2+: Pilot & Deploy.
- Start a formal pilot project. If self-hosting, begin with the infrastructure provisioning and model optimization steps from the checklist.
- Integrate the model into a staging environment. Conduct security and load tests.
- Plan a controlled production rollout with clear success metrics and a rollback plan.
Ignoring the DeepSeek open source model shift means ceding a cost and capability advantage to competitors who act. Start your evaluation today. The frontier of open-source AI is here, and it’s ready for deployment.


