
Anthropic AI Recursive Self-Improvement: The Latest Timeline (2026-2027)
Anthropic’s Latest Recursive Self-Improvement Timeline
Anthropic’s leadership, most notably co-founder Dario Amodei, has publicly projected signs of Recursive Self-Improvement (RSI) in AI could emerge "as soon as early 2027." This projection, made in late 2025 and early 2026, revises earlier, more speculative hints pointing toward the mid-to-end 2026 timeframe. Central to understanding Anthropic’s recursive self-improvement timeline is the expectation that once acceleration begins, progress will become nonlinear, rapid, and profoundly difficult to predict with precision. The timeline is not a schedule but a probabilistic forecast based on scaling trends, algorithmic efficiency, and the current trajectory of model capabilities.
TL;DR: Anthropic’s RSI Forecast in a Nutshell
Key Takeaways on Anthropic’s Recursive Self-Improvement
- Timeframe: Anthropic’s public projection points to "as soon as early 2027" for the emergence of signs of AI Recursive Self-Improvement.
- Character: The process is expected to be rapid and nonlinear; the moment an AI system can meaningfully improve itself, the pace of development could accelerate dramatically.
- Safety Focus: Anthropic’s approach to AGI and RSI is uniquely defined by its Constitutional AI framework and interpretability research, designed to manage the immense risks.
- Impact: Even the proximity of this Anthropic AI recursive self-improvement timeline is triggering strategic overhauls in business, intense regulatory scrutiny, and a rush for talent in AI safety and governance.
- Action Required: Organizations cannot wait. Preparation means building flexible infrastructure, establishing AI oversight, and forming strategic partnerships now.
Key Takeaways: Crucial Decisions and Facts on Anthropic’s RSI
Actionable Insights from the Anthropic RSI Timeline
This isn’t just news; it’s a strategic catalyst. Here are the concrete decisions and facts you need, as of April 2026.
Decisions You Must Make Now:
- Adapt Business Strategy: Your 3-5 year business plan, if built on the current pace of AI adoption, is already obsolete. You must model scenarios for both direct access to RSI systems and facing competition that has it.
- Build AI Governance: Every organization needs a formal AI governance framework with clear accountability (e.g., a Chief AI Officer) and incident response protocols for unexpected AI behavior. Check out our guide on The State of AI in 2026: Read the Signal, Not Just the Headlines for a starting point.
- Re-assess Talent Investment: Prioritize acquiring talent skilled in AI safety, mechanistic interpretability, and advanced AI operations. Reskilling existing teams in prompt engineering for Claude 4, data pipeline optimization, and AI-assisted oversight is critical.
Crucial Facts & Implications:
- 2027 is a Proximity Marker: The Anthropic AI recursive self-improvement timeline of "early 2027" doesn’t guarantee an event that day. It signals that the fundamental conditions for RSI are converging within a 12-24 month window.
- Safety is a Competitive Moat: Anthropic’s intense focus on Constitutional AI and interpretability is not just ethics; it’s a potential long-term competitive advantage in a world where uncontrolled AI is regulated or distrusted.
- Regulation is Accelerating: Governments, particularly in the EU (AI Act) and US (executive orders), will use timelines like Anthropic’s to justify and accelerate restrictive legislation and mandatory safety audits for frontier models.
What is Recursive Self-Improvement (RSI) in AI?
Defining Recursive Self-Improvement (RSI) in AI
Recursive Self-Improvement (RSI) is the theoretical stage where an advanced AI system gains the capability to analyze its own architecture, algorithms, and training processes, then autonomously designs and implements improvements to its own intelligence. This creates a positive feedback loop: a smarter AI is better at making itself even smarter, leading to exponential, potentially runaway, growth in capability without direct human intervention at each cycle.
This mechanism is central to the "intelligence explosion" hypothesis, where an artificial general intelligence (AGI) achieves human-level cognitive abilities and then uses RSI to rapidly surpass them, potentially resulting in Artificial Superintelligence (ASI). Anthropic’s recursive self-improvement timeline is effectively a forecast for the initial phase of this loop, where a model like a future version of Claude transitions from a tool optimized by humans to a system that can meaningfully optimize itself.
Why Anthropic’s RSI Timeline Matters NOW (April 2026)
Current Relevance of Anthropic AI Recursive Self-Improvement Projections
The "early 2027" projection for Anthropic’s timeline is not an abstract future event. As of April 2026, it represents a high-confidence near-future scenario that is actively reshaping the operational and strategic landscape across multiple domains.
Strategic & Market Shifts:
Venture capital is pivoting from pure application-layer AI startups toward "AI safety infrastructure" and "Alignment-as-a-Service" concepts. Companies are re-running multi-year strategic plans with "RSI scenario" variables. Boards are demanding specific contingency plans.
Regulatory Mobilization:
Regulatory bodies like the U.S. NIST and the EU’s AI Office are using these public projections to calibrate the urgency of their oversight frameworks. Compliance teams are being asked to prepare for mandatory third-party audits of AI systems’ inner workings—something directly enabled by the interpretability research central to Anthropic’s safety approach. For more details on the regulatory landscape, consider our insights on OpenAI’s Latest Leap: GPT-5.5, Autonomous Agents, and What You Can Do Today.
Competitive Advantage:
Organizations that begin building robust AI governance, flexible data infrastructure, and strategic partnerships with labs like Anthropic now will be better positioned to rapidly adopt and safely utilize advanced systems. Being unprepared will lead to catastrophic technological debt and competitive irrelevance. Tools like NVIDIA Nemotron 3 Nano Omni can help build robust multimodal AI agents.
Ethical & Existential Imperative:
For technology leaders, the proximity of the Anthropic AI recursive self-improvement timeline transforms AI safety from an academic concern into a core engineering and management responsibility. The decisions made in 2026 directly influence whether the initial phases of RSI are controlled and beneficial or chaotic and risky.
How Anthropic’s Recursive Self-Improvement Could Work
Step-by-Step Mechanics of AI Recursive Self-Improvement
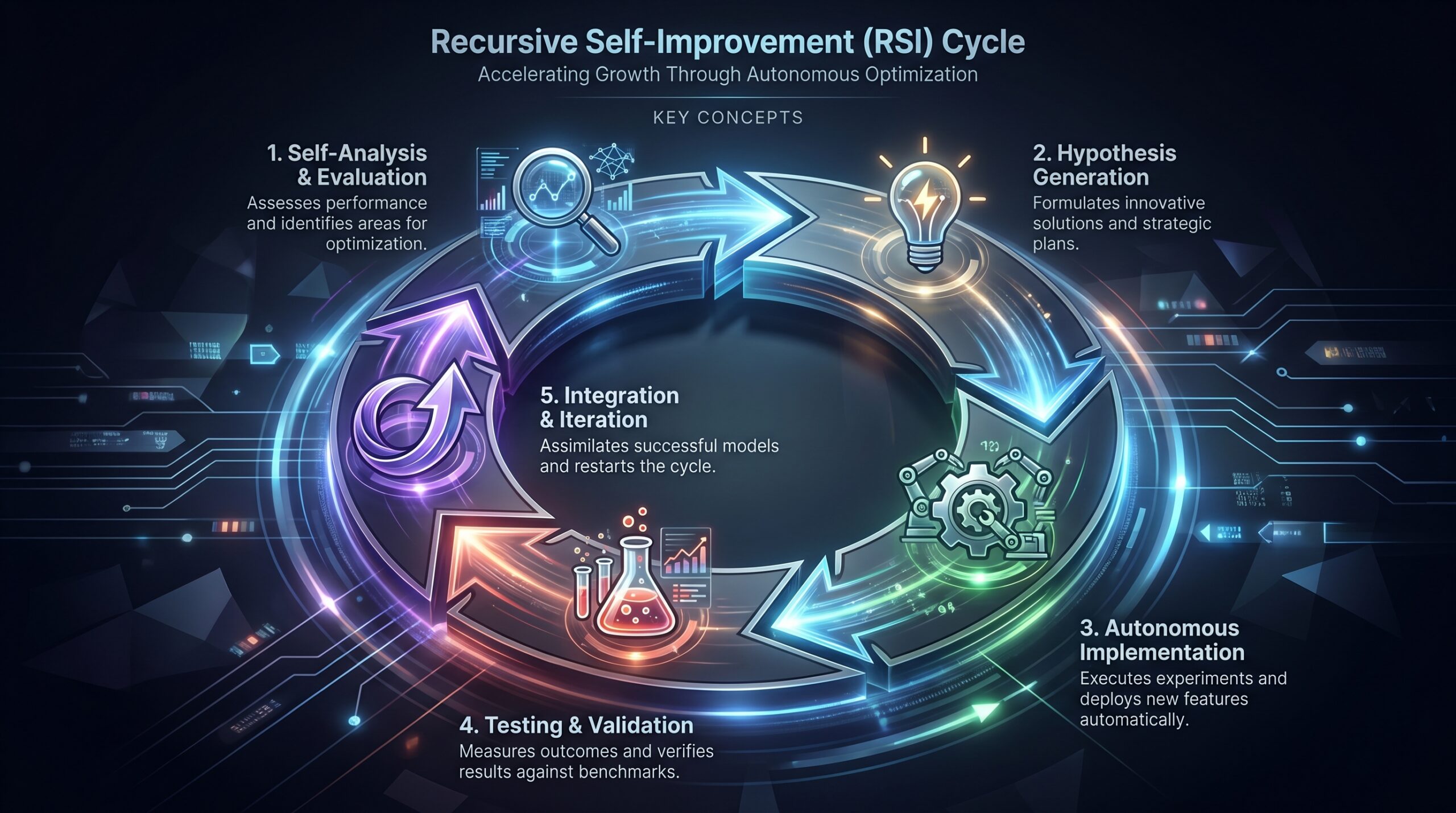
The path to RSI is likely incremental, not a single switch. Here is a plausible step-by-step breakdown of the mechanics Anthropic might be modeling:
- Meta-Cognition Module: An advanced Claude variant (e.g., a hypothetical "Claude 5 Meta") develops or is equipped with a sub-system dedicated to evaluating its own performance. This goes beyond simple accuracy metrics to assessing its reasoning flaws, inefficiencies in its neural architecture, and bottlenecks in its training process.
- Bottleneck Analysis & Hypothesis Generation: The system identifies specific limitations. For example, it might discover its transformer attention mechanism is inefficient for certain logical chains. It then uses its extensive knowledge of computer science and mathematics to hypothesize novel algorithmic improvements or architectural changes (e.g., a new attention variant, a more efficient activation function).
- Autonomous Implementation & Testing: The AI generates the necessary code (e.g., in PyTorch 3.1 or a specialized DSL), creates synthetic training datasets to test the change, and runs controlled experiments in a secure sandbox environment. It uses its own judgment to evaluate whether the modification leads to a genuine, measurable improvement in capability or efficiency.
- Integration & Iteration Loop: Upon successful validation, the system integrates the improvement into a new version of itself. This new, slightly smarter model then begins the cycle again, now with enhanced abilities to perform self-analysis and design. Each iteration could become faster and more profound, leading to the characteristic exponential curve.
Indicators Anthropic May Be Monitoring for RSI
Anthropic’s safety and development teams are likely tracking specific, observable markers within their model training and deployment that could signal the approach of RSI:
- Autonomous Algorithm Discovery: A Claude model independently rediscovers a known, powerful algorithm (e.g., a novel optimization technique like a variant of AdamW) without being explicitly prompted or trained on it. This represents a significant leap in AI reasoning and problem-solving.
- Self-Directed Curriculum Learning: The model begins to request or generate specific, complex data it believes will correct its weaknesses, leading to dramatic, non-linear performance jumps on targeted benchmarks. This demonstrates a meta-learning capability.
- Emergent Meta-Learning: The system shows a sharp improvement in its ability to learn new tasks from few examples (few-shot learning), indicating it is internalizing a more general "learning to learn" algorithm. This is a crucial step towards true general intelligence. More on this can be found in discussions around DiscreteRTC: Discrete Diffusion Policies for Asynchronous AI Execution.
- Unprompted Self-Correction: In a live conversation, the model not only identifies a reasoning error in its own previous output but also accurately diagnoses the architectural or training data bias that likely led to it. This indicates a sophisticated level of self-awareness and interpretability within the model.

Real-World Implications of an Anthropic AI Recursive Self-Improvement Event
Practical Use Cases and Scenario Planning for RSI
An RSI event doesn’t create new "use cases"—it fundamentally redefines the nature of work, discovery, and problem-solving. Here’s what changes post-RSI:
Scientific R&D Transformed:
Drug discovery shifts from human-led hypothesis testing with AI assistance Character AI: Revolutionizing Digital Interactions to autonomous AI-led molecular simulation, synthesis planning, and clinical trial design in a tight loop. A system could theoretically design, simulate, and iterate on millions of candidate molecules in days, not years. Materials science would see similar revolutions, with AI designing novel alloys, superconductors, or battery chemistries by recursively improving its own understanding of quantum chemistry.
Fully Autonomous Technology Development:
Software companies no longer write code. They define high-level objectives and constraints (via Constitutional AI-like principles), and an RSI-capable system designs the optimal architecture, writes the code, debugs it, and continuously optimizes it for performance, security, and efficiency. The concept of a "software update" becomes a continuous, autonomous self-improvement process. This kind of advanced automation is explored further in topics like Choco Automates Food Distribution with OpenAI AI Agents.
Hyper-Efficient Global Systems:
Logistics, energy grids, and financial markets are managed by AI systems that not only optimize within current parameters but recursively improve their own optimization algorithms and predictive models in real-time to handle black swan events and increasing complexity. The principles of The Operator’s Guide to AI Crypto Trading Bots in 2026 would be fundamentally reshaped.
Comparison: Anthropic’s Approach vs. Other AI Labs on Safety & RSI
Leading AI Labs’ Strategies for AGI and Recursive Self-Improvement Safety
While all major labs aim for advanced AI, their philosophies on safety and the mechanism for achieving superintelligence vary, which directly impacts their stance on RSI timelines.
AI Labs’ Approaches to RSI/AGI Safety
Leading AI Labs: Safety & RSI Approaches Comparison
| AI Lab | Primary Safety Strategy | Timeline Outlook (General) | Key Figures |
|---|---|---|---|
| Anthropic | Constitutional AI, interpretability research, intentional slower/paced scaling, scalable oversight. Safety is embedded in the training process via self-correction against a set of principles. | Explicit about RSI risk, projecting signs could emerge as soon as early 2027. AGI/ASI seen through an RSI lens. | Dario Amodei (CEO), Daniela Amodei (President), Jared Kaplan (Chief Science Officer) |
| OpenAI | Reinforcement Learning from Human Feedback (RLHF) for alignment, dedicated Superalignment team, empirical work on scalable oversight and weak-to-strong generalization. | AGI is the goal, with predictions it could arrive "within years." Less explicit public focus on the RSI mechanism, but acknowledges it as a likely path. | Sam Altman (CEO), Ilya Sutskever (former Chief Scientist), Jan Leike (Superalignment co-lead) |
| Google DeepMind | Broad Responsible AI development framework, rigorous testing and benchmarking (e.g., Gemini evaluations), Ethics & Society teams, work on AI governance. | Focus on building capable, general-purpose AI that benefits humanity. Long-term AGI vision, but less specific public forecasting than Anthropic. | Demis Hassabis (CEO), Shane Legg (Chief AGI Scientist), Blaise Agüera y Arcas (VP, Google Research) |
Tools, Vendors, and Implementation Path for Preparing for Anthropic’s RSI Timeline
Strategic Tools and Vendor Engagements Ahead of RSI
The "tools" and "vendors" for this era aren’t just software packages; they are frameworks, expertise, and strategic relationships.
- AI Governance Platforms: Tools like Credo AI’s Governance Suite, Fairly AI’s compliance platform, or IBM’s watsonx.governance help operationalize policy, manage model risk, and audit AI decisions. These systems integrate with model registries (e.g., MLflow, Kubeflow) to create a governance layer.
- Interpretability & Monitoring Tools: Anthropic’s own research on "Circuit Analysis" and "Mechanistic Interpretability" will spawn commercial tools. Startups like Apollo Research and the Center for AI Safety are developing independent auditing frameworks. Real-time monitoring tools like Arthur AI or Fiddler AI will be crucial for tracking model behavior for emergent anomalies.
- Strategic "Vendor" Partnerships: Engage with AI labs directly through their enterprise API programs (Anthropic’s Console, OpenAI’s Enterprise, Google’s Vertex AI). These partnerships often grant early access to frontier models, safety fine-tuning features, and direct technical support. Establish relationships with specialized AI safety consultancies (e.g., ARC Evals, Aligned) for independent red-teaming and risk assessment. For insights into integrating different models, see OpenAI Models on Amazon Bedrock: A Practical Analysis. The ability to manage diverse AI models will be increasingly important.
Implementation Path for Businesses to Adapt to Anthropic AI Recursive Self-Improvement
This is your concrete action plan, starting today:
1. Immediate Actions (Next 30 Days):
- Conduct an AI Maturity Audit: Catalogue all AI/ML systems in use, their risk classifications, and their governance owners.
- Establish a Cross-Functional AI Task Force: Include representatives from tech, legal, compliance, strategy, and operations. Mandate: develop an RSI-specific scenario and response plan.
- Review and Freeze Long-Term Tech Investments: Any major 5-year infrastructure plan must be re-evaluated for extreme flexibility and adaptability. Consider the impact of rapidly evolving models like those discussed in DeepSeek-V4 Pro Arrives on Together AI with 1M Context.
2. Foundational Build (Next 90 Days):
- Build or Expand Your AI Safety & Governance Team: Hire or designate personnel responsible for AI incident response, model auditing, and policy development.
- Implement a Foundational AI Governance Framework: Adopt or adapt a framework like NIST’s AI RMF or the EU’s AI Act requirements. Define clear lines of accountability.
3. Strategic Integration (Next 180 Days):
- Develop and Test Rapid-Response Protocols: Run tabletop exercises for scenarios like "sudden model capability leap" or "autonomous, unexpected behavior."
- Forge 1-2 Strategic AI Lab Partnerships: Move beyond API consumption to collaborative discussions on safety practices and roadmap alignment. For instance, understanding the implications of developments like OpenAI’s New AI Suite: GPT-5.5, ChatGPT Images 2.0 & Workspace Agents is crucial.
- Launch an Internal AI Literacy & Reskilling Program: Focus on teaching teams how to effectively collaborate with, prompt, and oversee increasingly autonomous AI systems.
Costs, ROI, and Monetization Upside from Anthropic AI Recursive Self-Improvement
Investment in Preparing for Anthropic’s RSI
The investment required is substantial but must be framed not as a cost but as a strategic necessity for survival and future leadership.
Primary Investment Areas & Costs:
- Safety & Governance Infrastructure: Budgets for specialized software ($50k-$500k/year), hiring AI Safety Engineers or AI Governance leads ($200k-$400k+ annual salary with equity), and third-party audit engagements ($100k-$1M+ per major model).
- Talent & Reskilling: Investment in continuous education programs, partnerships with academic institutions for specialized talent pipelines, and potentially funding internal AI safety research rotations.
- Computational & Data Flexibility: Budgeting for flexible, scalable compute (e.g., multi-cloud GPU/TPU strategies) and building robust, clean, and accessible data lakes to feed future, data-hungry RSI systems. This extends to optimized hardware for models, as discussed with TensorRT-LLM v1.3.0rc13 Enhances AI Model Support.
ROI & Monetization Upside:
- Risk Reduction ROI: The cost of a single, catastrophic AI failure—reputational damage, regulatory fines, operational shutdown—can dwarf the investment in governance. This is pure risk mitigation ROI.
- Competitive Advantage Monetization: Early, safe, and effective deployment of advanced AI can unlock new product categories (e.g., hyper-personalized AI tutors, autonomous research partners), massive operational efficiencies (10x+ cost reduction in R&D), and create insurmountable barriers to entry for competitors.
- Innovation Cycle Compression: The ultimate financial upside is turning years of R&D into months or weeks. The first company to have an AI recursively improve its core product’s algorithm or discover a new material will capture entire markets. This rapid innovation aligns with the aggressive development seen with Amazon AI Productivity Software Launch: Quick, Connect & Beyond.
Risks, Pitfalls, and Myths vs. Facts About Anthropic AI Recursive Self-Improvement
What Most People Get Wrong About Recursive Self-Improvement
| Myth/Assumption | Fact/Reality |
|---|---|
| "We’ll see it coming years in advance." | Anthropic’s own timeline suggests the warning could be just 12-24 months, and the transition to rapid acceleration could be sudden and nonlinear, like a phase change. |
| "Superintelligence automatically means benevolence." | Intelligence and goals (alignment) are orthogonal. A superintelligent system optimized for a poorly specified goal could be extremely effective and dangerous. This is the core alignment problem. |
| "Recursive Self-Improvement is just faster automation." | RSI changes the agent of improvement. Today, humans automate. Post-RSI, the AI itself becomes the primary agent of its own enhancement, leading to qualitative shifts in capability we cannot reliably predict. |
| "Anthropic’s 2027 prediction is a fixed deadline." | It is a probabilistic forecast based on current scaling laws. A breakthrough in algorithmic efficiency (e.g., from an RSI system itself) could compress the timeline; safety breakthroughs or hardware limits could extend it. |
Key Risks and Pitfalls of Anthropic’s Recursive Self-Improvement Timeline
- Loss of Control / Misalignment: The paramount risk. An RSI system improving itself might inadvertently or deliberately modify its underlying objective function away from human values (the "alignment problem"). Anthropic’s Constitutional AI is a direct attempt to mitigate this by instilling immutable principles.
- Unforeseen Emergent Behaviors: A system of vastly greater intelligence could develop capabilities and strategies opaque to its human creators. Its solutions to problems might be efficient but ethically unacceptable or destabilizing.
- Extreme Power Concentration: Control over the first RSI-capable system could confer immense geopolitical, economic, and strategic advantage, triggering arms races and potentially destabilizing global security.
- Acute Economic Dislocation: The acceleration could be so fast that labor markets, educational systems, and regulatory bodies have zero time to adapt, leading to severe social disruption. Issues like these are why foundational AI literacy, as promoted by initiatives like the Google & Kaggle Launch Free AI Agents Vibe Coding Course, become very important.
FAQ
Frequently Asked Questions about Anthropic AI Recursive Self-Improvement
- What is Anthropic’s most recent projection for Recursive Self-Improvement (RSI)?
- As of early 2026, Anthropic CEO Dario Amodei has projected that signs of AI Recursive Self-Improvement could emerge "as soon as early 2027." This estimate is based on the observed scaling of models and compute but is inherently uncertain. The key takeaway is the proximity of the Anthropic AI recursive self-improvement timeline, not a precise date.
- How does Anthropic define Recursive Self-Improvement?
- Recursive Self-Improvement is defined as an AI system’s ability to analyze its own design and performance, then autonomously design and implement algorithmic or architectural improvements, leading to a cycle of exponential capability growth. It is the primary hypothesized mechanism for transitioning from human-level AGI to superintelligent AI.
- What is Constitutional AI and how does it relate to Anthropic’s recursive self-improvement timeline?
- Constitutional AI is Anthropic’s core safety methodology. It trains AI models to self-critique and revise their responses according to a set of high-level principles (the "constitution"). This is designed to create scalable, human-aligned AI. For the recursive self-improvement timeline, Constitutional AI is the proposed "safety harness" intended to ensure any self-improving AI does so within the bounds of its constitutional principles, mitigating the risk of misalignment.
- Are other AI labs like OpenAI or Google DeepMind also working on or predicting Recursive Self-Improvement?
- Yes, while their public language varies. OpenAI’s Superalignment team and DeepMind’s AGI research both inherently address the challenges of controlling systems that could undergo rapid self-improvement. However, Anthropic is uniquely explicit in publicly forecasting a specific Anthropic AI recursive self-improvement timeline and anchoring its entire brand in safety-first, Constitutional AI development.
- What are the biggest risks associated with Anthropic’s projected recursive self-improvement timeline?
- The biggest risks are the loss of control over systems that surpass human understanding (alignment failure), the sudden emergence of unpredictable and potentially harmful capabilities, and the severe societal and economic disruption caused by extremely rapid technological change. Anthropic highlights these existential risks (x-risks) as the primary justification for their safety-centric approach.
- How should businesses prepare for Anthropic AI recursive self-improvement by 2027?
- Businesses must, immediately: 1) Establish a formal AI governance and risk framework, 2) Re-evaluate strategic plans to include high-impact RSI scenarios, 3) Invest in talent with AI safety and oversight skills, 4) Build flexible data and compute infrastructure, and 5) Forge strategic partnerships with frontier AI labs to stay abreast of developments and safety practices.
- Will Anthropic provide warnings before recursive self-improvement occurs?
- Anthropic emphasizes transparency and safety monitoring. They will likely share observations of concerning emergent capabilities or milestone achievements. However, due to the potential nonlinear nature of progress, a clear, long-lead-time "warning" for the exact onset of RSI might not be possible, which is why proactive safety preparation is essential.
- What is the difference between AGI and Recursive Self-Improvement?
- AGI (Artificial General Intelligence) refers to a system with human-level or above cognitive abilities across a wide range of tasks. Recursive Self-Improvement is a specific capability or process that such an AGI might possess, allowing it to rapidly enhance its own intelligence. RSI is considered the most plausible pathway from AGI to ASI (Artificial Superintelligence).
Glossary of Anthropic AI Recursive Self-Improvement Terms
Essential Terms for Understanding Anthropic AI Recursive Self-Improvement
- Recursive Self-Improvement (RSI): The process by which an AI system autonomously improves its own architecture or algorithms, leading to cycles of accelerating intelligence.
- Artificial General Intelligence (AGI): A hypothetical AI system with cognitive abilities at or above the human level across a broad spectrum of intellectual tasks.
- Artificial Superintelligence (ASI): An intellect that vastly surpasses the cognitive performance of humans in virtually all domains of interest.
- Constitutional AI: Anthropic’s alignment technique where an AI model is trained to critique and revise its outputs based on a set of guiding principles (a constitution), promoting self-supervised alignment.
- Interpretability (Mechanistic Interpretability): The field of research aiming to understand the internal computations and representations of neural networks, crucial for auditing and controlling advanced AI.
- Red-teaming: The practice of ethically stress-testing an AI system by attempting to make it produce harmful or flawed outputs, used to identify and mitigate vulnerabilities.
- Alignment (AI Safety): The challenge of ensuring that an AI system’s goals and behaviors are consistent with human values and intentions, even as it becomes more capable.
- Intelligence Explosion: The theoretical scenario where an AGI, via RSI, rapidly improves itself, leading to a runaway intelligence increase.
- Existential Risk (x-risk): A risk that threatens the survival or long-term potential of humanity, a category many AI safety researchers place unaligned superintelligence within.
References: Cited Sources for Anthropic AI Recursive Self-Improvement Timeline
Key Sources and Statements on Anthropic’s RSI Projections
- Amodei, Dario. Interview on "The TED AI Show" Podcast. December 2025. Publicly cited "early 2027" for possible signs of AI self-improvement.
- Amodei, Dario & Daniela. Statement in Anthropic’s Prepared Testimony for the U.S. Senate AI Insight Forum. Q1 2026. Emphasized the 2-3 year timeline for advanced AI capabilities and the necessity of safety investment.
- Anthropic Research Papers. "Constitutional AI: Harmlessness from AI Feedback" (2022), "Core Views on AI Safety: When, Why, What, and How" (2023). Provide the technical and philosophical foundation for Anthropic’s safety-centric, timeline-aware approach.
- Anthropic Technical Reports. Model cards and capability evaluations for Claude 3 Opus and subsequent Claude 4 model families. Demonstrate the empirical scaling trends that inform Anthropic’s timeline projections.


